Transactional Tables / ACID Properties in Hive 🐝When dealing with transactional data, it’s crucial to use a system that supports ACID compliance. ACID stands for Atomicity, Consistency…Jan 27Jan 27
Optimizing Data Processing with Hive: A Look at Partitioning, Bucketing, and Join Optimizations 📊Apache Hive is a powerful tool 🛠️ for data querying and analysis on large datasets stored in Hadoop. However, as with any tool, getting…Jan 13Jan 13
Understanding Hive Tables: Managed and External 🐝Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. Hive gives an…Jan 8Jan 8
Apache Hive: A Comprehensive Guide 🐝Apache Hive is an open-source data warehouse system built on top of Hadoop for providing data query and analysis. Hive gives an SQL-like…Dec 25, 2024Dec 25, 2024
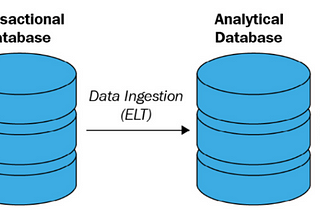
Transactional System Vs Analytical System: A Comparative Study 🚀In the world of data, understanding the difference between Transactional and Analytical Systems is crucial. Let’s dive into each of these…Dec 20, 2024Dec 20, 2024
File Compression Techniques in Apache SparkIn the world of Big Data, managing storage space and reducing I/O costs are crucial for efficient data processing. One of the ways to…Dec 16, 2024Dec 16, 2024
Schema Evolution in Apache SparkSchema evolution is particularly important in Big Data systems where data is often stored in a schema-on-read format like Parquet or Avro…Dec 10, 2024Dec 10, 2024
Compression Techniques in Apache SparkApache Spark supports several light-weight compression techniques that can significantly reduce the size of your data, making it faster and…Dec 4, 2024Dec 4, 2024